Why Multicalibration?
Machine learning models are increasingly used to make decisions that affect people, content, and business outcomes. For these systems, calibration—ensuring that predicted probabilities match real-world outcomes—is essential for trust, fairness, and optimal decision-making.
However, global calibration alone is insufficient. Even a well-calibrated model on average can systematically overestimate or underestimate for specific segments (also known as protected groups)—such as users in a particular country, transactions on a certain device, or content of a certain type. These hidden calibration gaps lead to unfair, unreliable, or suboptimal decisions for affected segments.
A Motivating Example
Consider a model trained to predict the likelihood of a user clicking on an ad. The reliability plot shows clear miscalibration, so you apply a global calibration method like Isotonic Regression. The resulting reliability plot looks nearly perfect.

Upon closer inspection, a different picture emerges. When examining two specific segments—US and non-US markets—the reliability plots reveal significant problems. For the US market, the model underestimates, predicting lower than the actual click rates. For non-US markets, the model overestimates, consistently predicting higher probabilities than reality.
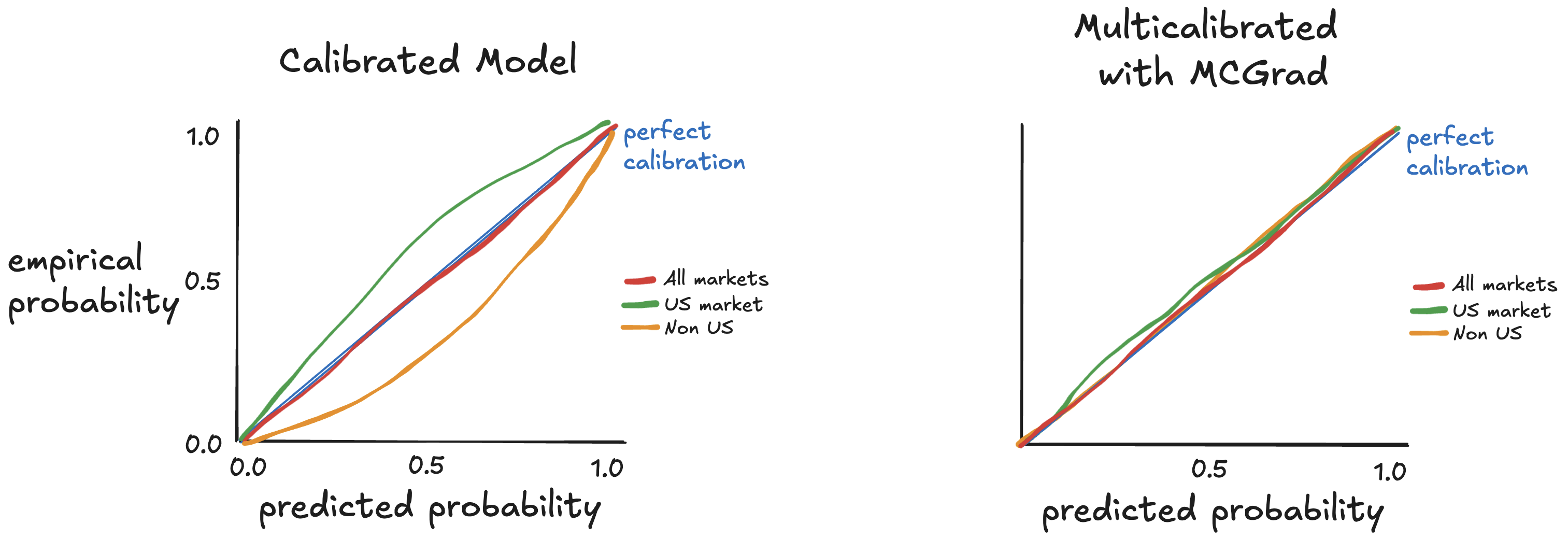
This is a common pitfall: global calibration can mask significant miscalibration within segments. These hidden errors have real consequences and lead to poor business outcomes.
After applying MCGrad instead of Isotonic Regression, the reliability plots for those same segments show curves much closer to the diagonal. Predictions for US and non-US markets now accurately reflect the true click rates. MCGrad does not just fix the model globally—it ensures every meaningful segment receives calibrated predictions.
MCGrad in Action
MCGrad automatically discovers and corrects miscalibrated regions defined by your features, including intersections like market=US AND device_type=mobile. There is no need to manually specify which segments to calibrate—simply provide your features, and MCGrad identifies and fixes calibration issues across all relevant segments.
from mcgrad import methods
# df is a DataFrame with columns:
# - 'prediction': the uncalibrated model predictions (floats in [0, 1])
# - 'label': the true binary labels (0 or 1)
# - categorical features such as 'market', 'device_type', or 'content_type'
# - optionally, numerical features such as 'age'
mcgrad = methods.MCGrad()
mcgrad.fit(
df_train=df,
prediction_column_name='prediction',
label_column_name='label',
categorical_feature_column_names=['market', 'device_type', 'content_type'],
numerical_feature_column_names=['age'], # MCGrad also supports continuous features
)
calibrated_predictions = mcgrad.predict(
df,
prediction_column_name='prediction',
categorical_feature_column_names=['market', 'device_type', 'content_type'],
numerical_feature_column_names=['age'],
)
The result: predictions calibrated globally AND for virtually any segment defined by your features.
MCGrad doesn't just improve calibration: it typically also improves predictive performance metrics like log-loss and PRAUC. Unlike Isotonic Regression, which can harm ranking metrics, MCGrad is a likelihood-improving procedure that preserves or improves overall model quality. See Why MCGrad? for details.
Get Started
- Why MCGrad? — Learn about the challenges MCGrad solves and see results.
- Installation — Step-by-step instructions for installing MCGrad.
- Quick Start — Complete example workflows with evaluation and visualization.
Citation
If you use MCGrad in academic work, please cite our paper:
@inproceedings{tax2026mcgrad,
title={{MCGrad: Multicalibration at Web Scale}},
author={Tax, Niek and Perini, Lorenzo and Linder, Fridolin and Haimovich, Daniel and Karamshuk, Dima and Okati, Nastaran and Vojnovic, Milan and Apostolopoulos, Pavlos Athanasios},
booktitle={Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 (KDD 2026)},
year={2026},
doi={10.1145/3770854.3783954}
}